

全文検索サーバー Fessの設定について


こんばんはTakeyemaです。
WEBサイトの制作で、PDFの全文検索が必要な案件があったのでFessという検索サーバーを立ててみました。
そのときに気づいたちょっとしたコツなどを備忘録として残します。
まだ勉強中ですので、間違っているところもあるかもしれませんが何かの参考になれば。
Fessはたいへん高機能な検索サーバーであり、動作も非常に高速。
それでいながら、設定画面なども使いやすく、設置も非常に簡単でした。
まずインストールは以下を参考にさせていただきました。
https://developer-collaboration.com/2019/06/03/fess-install1/
いきなり他所様の引用で申し訳ないですが、ほぼこちらの内容で問題なく設置できました。
ハマりがちなjavaも問題なく行けました。大助かりです。
設定はブラウザから「fessのIPまたはドメイン:8080」から行います。
とりあえず検索を試すには、左のメニューから クローラ→ウェブ と進み、右上の新規作成を押します。
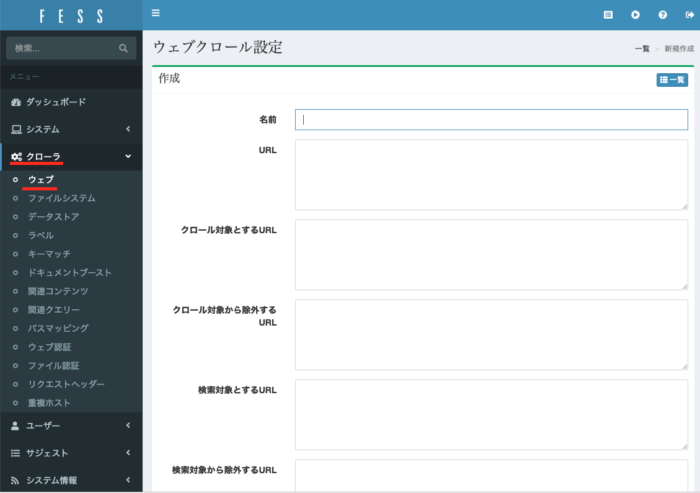
お試しですので、適当な名前を入れてURL、クロール対象とするURLを入れれば、とりあえずドキュメントルートからクロールする設定ができます。
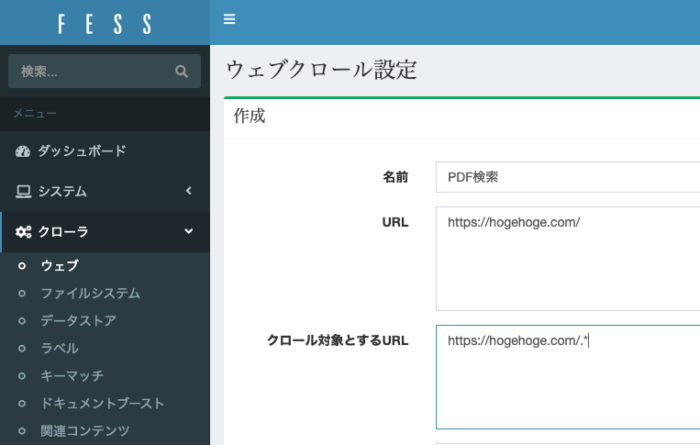
クロール対象とするURLは、検索対象としたい一番上の階層のURLを入れて末尾に.*と書けばOK。
ここで注意しなければいけないのは、wwwありかなしかについてです。
.htaccessなどで正しい表記の方にリダイレクトする設定を入れている場合が多いと思いますが、
たとえば、「wwwナシ」を「wwwアリ」にリダイレクトしてる場合、
Fessの対象URLにwwwナシを設定してもFessはそこにたどり着けません!
まあ考えてみりゃそりゃそうだよな、、というところですが。
ここにつまずいて1時間くらい試行錯誤したのは私です。。
さて、これでスケジューラから「Default Crawler」を開始すればクロールが開始するのですが、
すべてのクローラが走ってしまいますので、今回はジョブを作成してそちらを走らせることにします。
クローラ→ウェブ からクローラの一覧が見れますので見れますので先程作ったクローラを選択します。
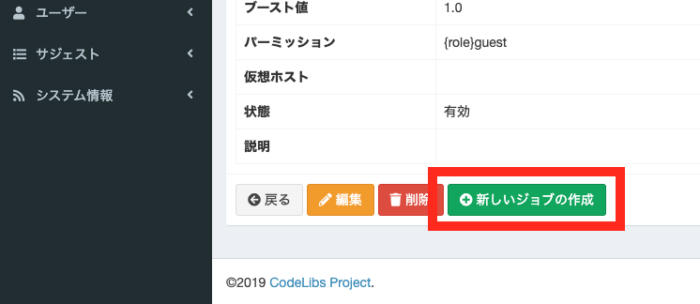
クローラの編集ができますが、一番下に「新しいジョブの作成」というボタンがあるのでこれを押します。
ジョブの設定をする画面が出ますが、今回はお試しなのでこのまま作成を押します。
これだけでジョブが作成されます。
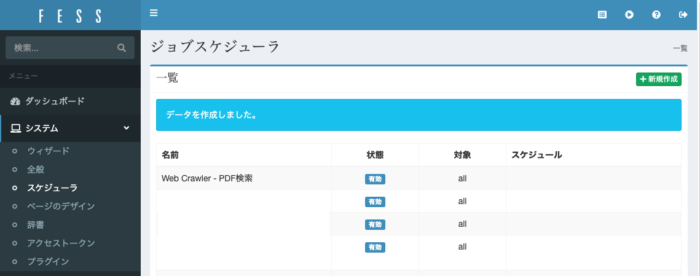
これを実行します。
システム→スケジューラから先ほど作成したジョブを選択します。
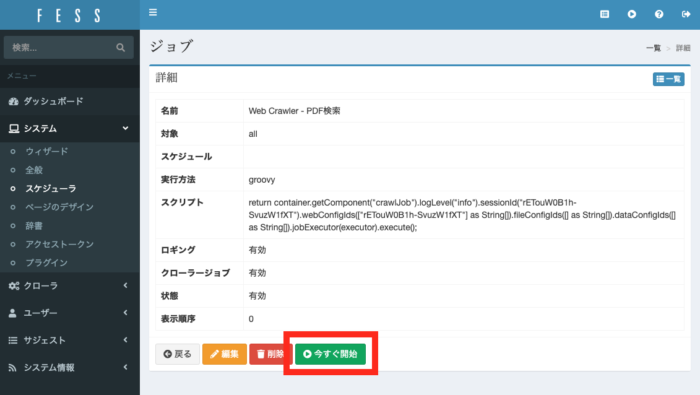
ここで「今すぐ開始」を押すとジョブが実行されます。
ジョブの実行状況は システム情報→ジョブログ から確認できます。
状態が実行中になっていればOKです。



